###向量
```r
#访问向量中元素
x <- 1:10;print(x)
--->
[1] 1 2 3 4 5 6 7 8 9 10
print(x[5])
--->
[1] 5
print(x[-5]) #除了第5个元素之外的所有元素
--->
[1] 1 2 3 4 6 7 8 9 10
print(x[c(1,5,8)])
--->
[1] 1 5 8
print(x[1:5])
--->
[1] 1 2 3 4 5
#冒号优先级更高,首先得到1-5这5个数据再乘以2
print(x[1:5*2])
--->
[1] 2 4 6 8 10
#逻辑表达式用x中每一个元素计算逻辑表达式的值做索引,得到的是原数组中x大于5的元素
print(x[x > 5])
--->
[1] 6 7 8 9 10
print(mean(x))
--->
[1] 5.5
#大于平均值的向量有哪些
print(x[x>mean(x)]) #逻辑表达中可以使用函数
--->
[1] 6 7 8 9 10
#使用字符常数数组给向量命名,再通过变量名访问向量中的元素
names(x) <- LETTERS[1:10];print(x) #给每一个向量命名
--->
A B C D E F G H I J
1 2 3 4 5 6 7 8 9 10
print(x["A"])
--->
A
1
View(x) #打开一个窗口看到数据
#计算向量的长度
print(length(x))
--->
[1] 10
#修改指定位置的向量元素
x <- 1:10;print(x)
--->
[1] 1 2 3 4 5 6 7 8 9 10
x[5] <- 100;print(x)
--->
[1] 1 2 3 4 100 6 7 8 9 10
#追加向量元素增加向量长度
x <- 1:10;print(x)
--->
[1] 1 2 3 4 5 6 7 8 9 10
x <-c(x,11,12,13);print(x)
--->
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13
#直接在向量末尾写入数据
> x <- 1:10;print(x)
[1] 1 2 3 4 5 6 7 8 9 10
> x[length(x)+1] <- 11;print(x)
[1] 1 2 3 4 5 6 7 8 9 10 11
#在向量指定位置插入数据
#并不是在原来的向量中插入数据而是返回一个新的向量
#after参数表示在原向量中的那个向量后面插入数据
> x <- 1:10;print(x)
[1] 1 2 3 4 5 6 7 8 9 10
> y <- append(x,11:13,after=0);print(x);print(y)
[1] 1 2 3 4 5 6 7 8 9 10
[1] 11 12 13 1 2 3 4 5 6 7 8 9 10
> y <- append(x,11:13,after=5);print(x);print(y)
[1] 1 2 3 4 5 6 7 8 9 10
[1] 1 2 3 4 5 11 12 13 6 7 8 9 10
```
###列表
```r
#访问列表
> lst <- list(symbols=c("MSFT","KO","CSCO"),price=c(40.40,40.56,23.02),currency="USD",country="USA",type="STOCK")
> print(lst[1])
$symbols
[1] "MSFT" "KO" "CSCO"
> print(lst$symbols)
[1] "MSFT" "KO" "CSCO"
#该列表的第一个元素是一个向量symbol
> print(lst[[1]])
[1] "MSFT" "KO" "CSCO"
#该列表中的symbols向量的第一个元素
> print(lst$symbols[1])
[1] "MSFT"
#在列表末尾添加一个新的元素TradeDte
> names(lst)
[1] "symbols" "price" "currency" "country" "type"
> lst$TradeDate <- as.Date(rep("2016-1-17",3))
> names(lst)
[1] "symbols" "price" "currency" "country" "type"
[6] "TradeDate"
#在列表任意位置添加一个新的元素
> z <- list(plantform = rep("FXCM",3))
> lst <- append(lst,z,after=0) #在首部增加元素
> names(lst)
[1] "plantform" "symbols" "price" "currency" "country"
[6] "type" "TradeDate"
> str(lst)
List of 7
$ plantform: chr [1:3] "FXCM" "FXCM" "FXCM"
$ symbols : chr [1:3] "MSFT" "KO" "CSCO"
$ price : num [1:3] 40.4 40.6 23
$ currency : chr "USD"
$ country : chr "USA"
$ type : chr "STOCK"
$ TradeDate: Date[1:3], format: "2016-01-17" ...
#删除列表中的指定项
> names(lst)
[1] "plantform" "symbols" "price" "currency" "country"
[6] "type" "TradeDate"
> lst$price <- NULL
> names(lst)
[1] "plantform" "symbols" "currency" "country" "type"
[6] "TradeDate"
```
###矩阵
```r
#矩阵访问
> data(EuStockMarkets) #欧洲股票
> print(head(EuStockMarkets))
DAX SMI CAC FTSE
[1,] 1628.75 1678.1 1772.8 2443.6
[2,] 1613.63 1688.5 1750.5 2460.2
[3,] 1606.51 1678.6 1718.0 2448.2
[4,] 1621.04 1684.1 1708.1 2470.4
[5,] 1618.16 1686.6 1723.1 2484.7
[6,] 1610.61 1671.6 1714.3 2466.8
>
> print(class(EuStockMarkets))
[1] "mts" "ts" "matrix"
>
> print(summary(EuStockMarkets))
DAX SMI CAC FTSE
Min. :1402 Min. :1587 Min. :1611 Min. :2281
1st Qu.:1744 1st Qu.:2166 1st Qu.:1875 1st Qu.:2843
Median :2141 Median :2796 Median :1992 Median :3247
Mean :2531 Mean :3376 Mean :2228 Mean :3566
3rd Qu.:2722 3rd Qu.:3812 3rd Qu.:2274 3rd Qu.:3994
Max. :6186 Max. :8412 Max. :4388 Max. :6179
#输出所有行,DAX列数据,直接使用列名称访问
> print(EuStockMarkets[,"DAX"])
Time Series:
Start = c(1991, 130)
End = c(1998, 169)
Frequency = 260
[1] 1628.75 1613.63 1606.51 1621.04 1618.16 1610.61 1630.75
[8] 1640.17 1635.47 1645.89 1647.84 1638.35 1629.93 1621.49
[15] 1624.74 1627.63 1631.99 1621.18 1613.42 1604.95 1605.75
[22] 1616.67 1619.29 1620.49 1619.67 1623.07 1613.98 1631.87
[29] 1630.37 1633.47 1626.55 1650.43 1650.06 1654.11 1653.60
[36] 1501.82 1524.28 1603.65 1622.49 1636.68 1652.10 1645.81
[43] 1650.36 1651.55 1649.88 1653.52 1657.51 1649.55 1649.09
[50] 1646.41 1638.65 1625.80 1628.64 1632.22 1633.65 1631.17
...
#输出所有行,第一列(德国DAX指数)数据,编写大型程序时显然不够直观
> print(EuStockMarkets[,1])
Time Series:
Start = c(1991, 130)
End = c(1998, 169)
Frequency = 260
[1] 1628.75 1613.63 1606.51 1621.04 1618.16 1610.61 1630.75
[8] 1640.17 1635.47 1645.89 1647.84 1638.35 1629.93 1621.49
[15] 1624.74 1627.63 1631.99 1621.18 1613.42 1604.95 1605.75
[22] 1616.67 1619.29 1620.49 1619.67 1623.07 1613.98 1631.87
[29] 1630.37 1633.47 1626.55 1650.43 1650.06 1654.11 1653.60
[36] 1501.82 1524.28 1603.65 1622.49 1636.68 1652.10 1645.81
[43] 1650.36 1651.55 1649.88 1653.52 1657.51 1649.55 1649.09
[50] 1646.41 1638.65 1625.80 1628.64 1632.22 1633.65 1631.17
...
#查看整个矩阵的数据,比较直观,清晰;坏处是还需要手动关闭打开的页面
View(EuStockMarkets)
#rowSums()计算矩阵每一行的和生成一个新向量
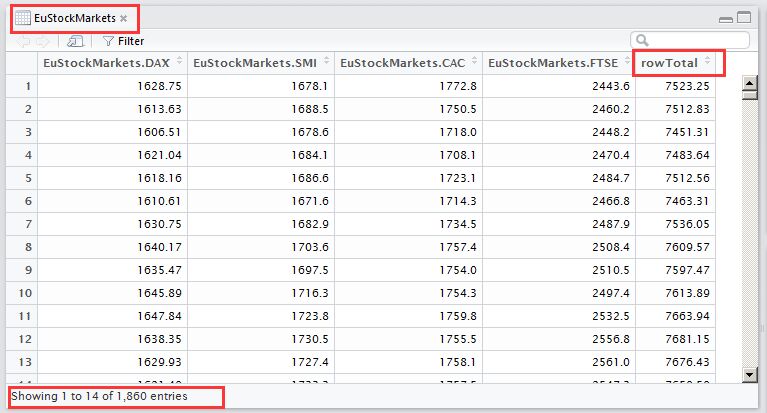
rowTotal <- rowSums(EuStockMarkets)
#以列方式将每一行和向量接在矩阵之后形成有5列的新矩阵
EuStockMarkets <- cbind(EuStockMarkets,rowTotal)
View(EuStockMarkets)
--->
如下图所示
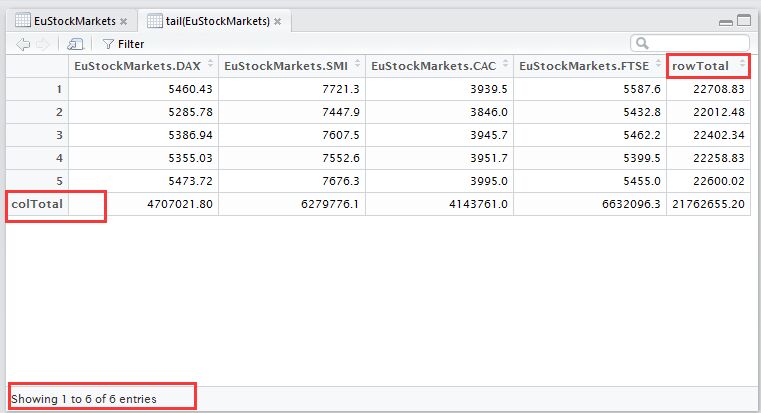
#colSums()计算矩阵每一列的和生成一个新向量
colTotal <- colSums(EuStockMarkets)
#以行的方式将每一行和向量接在矩阵之后,形成一个有新累加和行的矩阵
EuStockMarkets <- rbind(EuStockMarkets,colTotal)
print(tail(EuStockMarkets))
--->
EuStockMarkets.DAX EuStockMarkets.SMI EuStockMarkets.CAC EuStockMarkets.FTSE rowTotal
5460.43 7721.3 3939.5 5587.6 22708.83
5285.78 7447.9 3846.0 5432.8 22012.48
5386.94 7607.5 3945.7 5462.2 22402.34
5355.03 7552.6 3951.7 5399.5 22258.83
5473.72 7676.3 3995.0 5455.0 22600.02
colTotal 4707021.80 6279776.1 4143761.0 6632096.3 21762655.20
View(tail(EuStockMarkets))
--->
如下图所示
```
###数据框
```r
> df <- data.frame(symbols=c("MSFT","KO","CSCO"),price=c(40.40, 40.56, 23.02),currency=rep("USD",3),country=rep("USA",3),type=rep("STOCK",3))
> df
symbols price currency country type
1 MSFT 40.40 USD USA STOCK
2 KO 40.56 USD USA STOCK
3 CSCO 23.02 USD USA STOCK
> print(class(df))
[1] "data.frame"
#通过行号访问数据框的一行
> print(df[1,])
symbols price currency country type
1 MSFT 40.4 USD USA STOCK
#通过行列号访问数据框的一列
> print(df[,2])
[1] 40.40 40.56 23.02
> print(df$price) #用列名称是更好,更直观的方式
[1] 40.40 40.56 23.02
#如果需要多次访问数据框中的数据列可以将数据框名称加入到搜索路径中
#这样就可以直接使用数据列名称
> attach(df) #将df加入到搜索路径中
> print(currency)
[1] USD USD USD
Levels: USD
> print(type)
[1] STOCK STOCK STOCK
Levels: STOCK
> detach(df) #将df从搜索路径清除
```